
In this post, we present the most important technologies that our partner IDENER is starting to use within MAGNO’s strategic approach.
The enhancement of packaging effectiveness and sustainability within the European Union’s food systems represents a crucial challenge, especially in the context of reducing plastic packaging pollution. To address this, MAGNO’s strategic approach consists of employing cutting-edge computational technologies to gather and analyze big amounts of data, which will feed into a Digital Twin designed to revolutionise packaging and business practices. Some of the selected methodologies – open-source Large Language Models (LLMs), open-source embeddings, and Retrieval-Augmented Generation (RAG) – will pave the way for the creation of a dynamic model that simulates and optimises packaging life cycles from production through end-of-life stages, including reuse and recycling.
1. Large Language Models (LLMs)
Large Language Models, commonly known as LLMs, are a type of general-purpose GenAI models designed to recognize and generate human-like text. They have been trained on vast datasets and using deep learning algorithms, particularly those based on transformer models, a category of neural networks which were introduced in 2017 [1]. Unlike traditional models that process words sequentially, transformers analyze words in relation to all the other words present in a sentence, which allows for more nuanced understanding and generation of text, enabling LLMs to interpret human language and, consequently, to perform tasks such as translation, code generation, sentiment analysis, or powering chatbots, among others.
![]()
Figure 1. The Transformer-model architecture [1]
However, employing LLMs comes with its challenges. The reliability of LLMs heavily depends on the quality of their training data. This means that if the data is biased or contains errors, these issues will likely be reflected in the model’s outputs. Additionally, LLMs are prone to “hallucinate”, that is to say, generate content that is convincingly worded but factually incorrect. This tendency is pronounced when the model lacks enough information to generate accurate responses but is nonetheless designed to maintain fluidity and coherence, prioritising the smoothness of the text over factual accuracy. These concerns underline the critical need for training LLMs with comprehensive, unbiased, and factual data to ensure they effectively perform the functions they were intended to.
2. Embeddings
Embeddings are a Natural Language Processing (NLP) mechanism to transform text into numerical vectors while preserving the underlying meaning, so that computers can effectively process and analyse them. They are designed to represent words or phrases in such a way that the distance between vectors corresponds to semantic similarity. This means that words used in similar contexts or with similar meaning are positioned closely within the vector space.
The process of creating embeddings begins with the gathering of large amounts of text data, aimed at training models on how words are used in diverse contexts. During training, these models adjust the position of each word in the embedding space based on their usage in the training data. The goal is to place words with similar meanings close together and words with different meanings farther apart. Typically, embeddings are set to a fixed dimensionality, commonly ranging from 50 to 300 dimensions, with each of them encoding nuanced aspects of the word’s meaning. This structured arrangement in high-dimensional space enables algorithms to perform more sophisticated tasks such as translation or sentiment analysis.
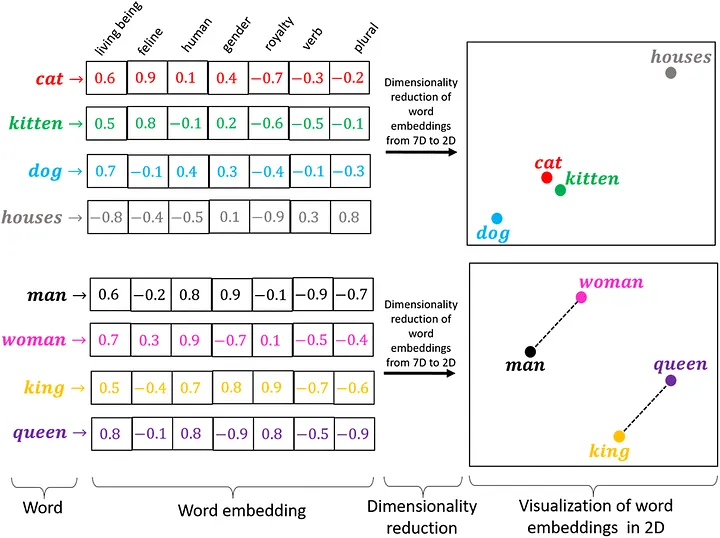
Figure 2. Word Embeddings [2]
3. Retrieval-Augmented Generation (RAG)
Retrieval-Augmented Generation (RAG) is an advanced architecture in Natural Language Processing that enhances the performance of LLMs by integrating them with the power of embeddings. As discussed above, LLMs are prone to generating inaccurate or irrelevant content, particularly when they are given queries that fall outside their training data. A common solution is to fine-tune the LLMs with data specific to the intended task, but this can be resource-intensive.
To bypass the need for retraining, RAG introduces an innovative approach by providing LLMs with additional contextual data tailored to the specific query. This is achieved by selecting relevant documents that are semantically close to the query. Moreover, by using embeddings for semantic search, RAG identifies and retrieves the text snippets – coming from the provided documents – that are most relevant to the query.
In practice, when a query is made, the RAG retrieves the most pertinent text chunks using semantic similarity metrics facilitated by embeddings. These chunks, together with the original query, are then fed into an LLM to provide an answer. Consequently, this reduces the model’s tendency to hallucinate, as the responses are now present in the retrieved content that is directly related to the query. This, in addition to the reduction in computational resources, makes RAG an efficient and practical solution in situations where precision is paramount.
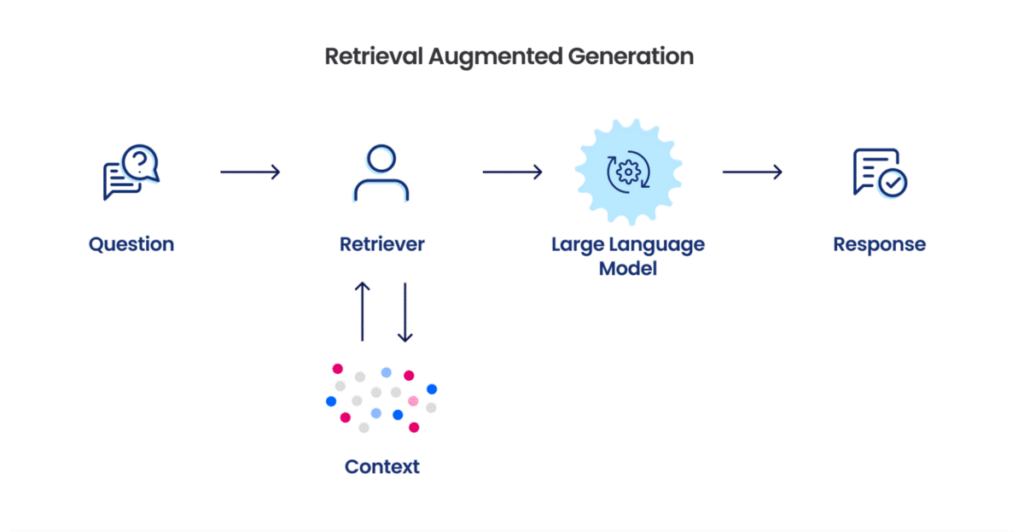
Figure 3. RAG pipeline [3]
References
| [1] | A. Vaswani, “Attention is all you need,” arXiv preprint arXiv:1706.03762, 2017. |
| [2] | H. Gautam, “Word Embedding: Basics,” 2020. [Online]. Available: https://medium.com/@hari4om/word-embedding-d816f643140. |
| [3] | H. Tran, “Which is better, retrieval augmentation (RAG) or fine-tuning? Both.,” 2023. [Online]. Available: https://snorkel.ai/which-is-better-retrieval-augmentation-rag-or-fine-tuning-both/. |





